Leverage GenAI to Categorize Articles Using Predefined Taxonomy

About
Hearst is a global, diversified information, media, and services company. Under Hearst magazine, there are 200+ magazine sites, including well-known brands such as Cosmopolitan, Esquire, Delish, and Men’s Health. As a media company, how does Hearst tap into the competitive e-commerce space that presents growing opportunities?
Given that the endless e-commerce options are only clicks away from any customers, Hearst saw an opportunity to capitalize on its reputation as a trusted review and information site; Hearst aims to launch a curated marketplace to create a “Commerce in Content” experience to elevate their reader experience, piloting with Men’s Health magazine and its associated Men’s Health Marketplace.
Objective
In order to better identify relevant product ads within content and linking marketplace products with relevant content, the objective is to develop an AI/ML solution that maps the article content to the predefined product taxonomy where relevant. An article can have many relevant taxonomy tags, and each taxonomy tag can be associated with many articles.
The solution must be scalable and flexible to accommodate for a growing and mutable marketplace taxonomy. Furthermore, the model should be easy to generalize to other magazines and taxonomies.
Tagging results have many use cases, such as ad placements and article recommendations within the marketplace.
Approach
Models:
We surveyed three models that ranged from traditional ML to cutting-edge AI technologies, which are 1) rule-based model, 2) embedding model, and 3) LLM model.
- Rule-based model: manually curates a list of keywords for each taxonomy and searches for keywords in article body
- Embedding model: converts sentence-wise article body and taxonomy into contextual embeddings and uses cosine-similarity score to identify most relevant tags
- LLM model: prompts GPT to pick out relevant taxonomies
Human-Labeled Data:
In order to benchmark and fine-tune our models, we needed labeled data. The team hang-tagged a total of 72 articles using the following steps:
- Use embedding model to narrow down potential tags (as original taxonomy is huge and can be hard to absorb for any individual)
- Each article is tagged by 3 analysts
- Aggregate results to create ground-truth labels by retaining tags chosen by at least 2 analysts
Evaluation Metrics:
In order to benchmark our model performance, we used two metrics to evaluate our models:
- Accuracy:
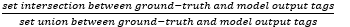
- Agreement score: Krippendorff’s alpha between ground-truth labels and model outputs
In addition to performance, we also considered operational cost, efficiency, and scalability of each model.
Solution
After much experimentation, we proposed the following model as a solution:
- Use embedding model to narrow down potential tags
- Pass the subset of tags and article into LLM using specific prompts (different prompts are needed for articles that directly promote products versus those that do not)
- LLM output final tags and their citations (if requested)
Impact
The shortcoming of a rule-based model is that it is extremely difficult to curate a comprehensive list of keywords for each taxonomy. For example, for taxonomy “fragrance”, a potential list would be “fragrance, perfume, cologne, etc”. Also, sometimes words may have more than one meaning. For example, gym “weights” may be incorrectly attributed to articles that discuss body weight loss strategies.
This weakness can be overcome by embedding and LLM models that consider word semantics. Moreover, similar to how a narrow set of potential tags were helpful for humans in tagging articles, we found similar improvements for LLM. Moreover, the LLM model also has the capability to output citation for each tag identified. This additional functionality did not jeopardize the output accuracy much and it provides transparency and explainability into LLM tagging results, allowing for model audit.
The solution we proposed demonstrates above-human performance. Also, upon closer inspection, we noticed that LLM outputs tags that actually are in the articles but are missing in the ground truth set. Most importantly, this model could be easily applicable to expanding taxonomy and new magazines as Hearst expands on this venture.


About the AI & Analytics Accelerator
Every fall and spring semester, Wharton AI & Analytics Initiative hosts the AI & Analytics Accelerator, an experiential learning program that pairs students with a company to solve a real-world business problem using the company’s actual datasets and the latest techniques including machine learning and AI.